Jak poradzić sobie z czasem na Arduino
Zmagania z czasem na Arduino potrafią uprzykrzyć życie, zwłaszcza początkującym. O czym piszę? O działaniach które mają być wykonywane przez jakiś czas albo dopiero po upłynięciu jakiegoś czasu.
Pierwsze podejście, kogoś kto rozpoczął swoją przygodę z Arduino będzie pewnie próba użycia delay. Hej, kto z nas tego nie próbował… Problem pojawia się wtedy gdy nasze Arduino musi coś robić w czasie czekania. A delay… no cóż, czekanie z delay to jest jedyna rzecz jaką może robić Arduino na raz.
Jak sobie poradzić z oczekiwaniem gdy musimy robić kilka rzeczy na raz?
By nie gadać po próżnicy, omówmy to na konkretnym przykładzie. Niedawno dla klienta robiliśmy urządzenie, które miało zliczać dane z czujników odległości. A konkretnie, chodziło o określenie ile osób przyłożyło głowę do urządzenia. Jeśli czujnik przez określoną liczbę sekund wskazywał dostatecznie mały odczyt, wówczas mieliśmy zliczyć osobę, która podeszła do czujnika. Podobnie, dopiero gdy na określoną ilość sekund oddaliła się od czujnika dopiero wtedy miało być zwolnione miejsce i czujnik miał być gotowy do zarejestrowania kolejnej osoby. Na dodatek – były dwa czujniki, które miały być obsługiwane jednocześnie.
Próba zbudowania tego na ifach jest raczej skazana na porażkę. Nie, że to nie da się tak zrobić, ale… zmiana wymagań, jak np dodanie jakiegoś kryterium czy nawet drobna zmiana zachowania urządzenia może oznaczać długie i mozolne grzebanie w kodzie.
Wybrnąć z takiej sytuacji pozwala zwykle model matematyczny określany nazwą maszyną stanów (lub automat skończony). W prostych słowach – mamy skończony zbiór stanów w których może znaleźć się nasz system. Do tego potrzebujemy określić warunki w jakich następują przejścia pomiędzy stanami.
Na początek, prosty przykład – klasyczny Blink. Czyli, mamy dwa stany – dioda zapalona i zgaszona. Przejście następuje gdy minie jedna sekunda. Można to zilustrować takim diagramem:
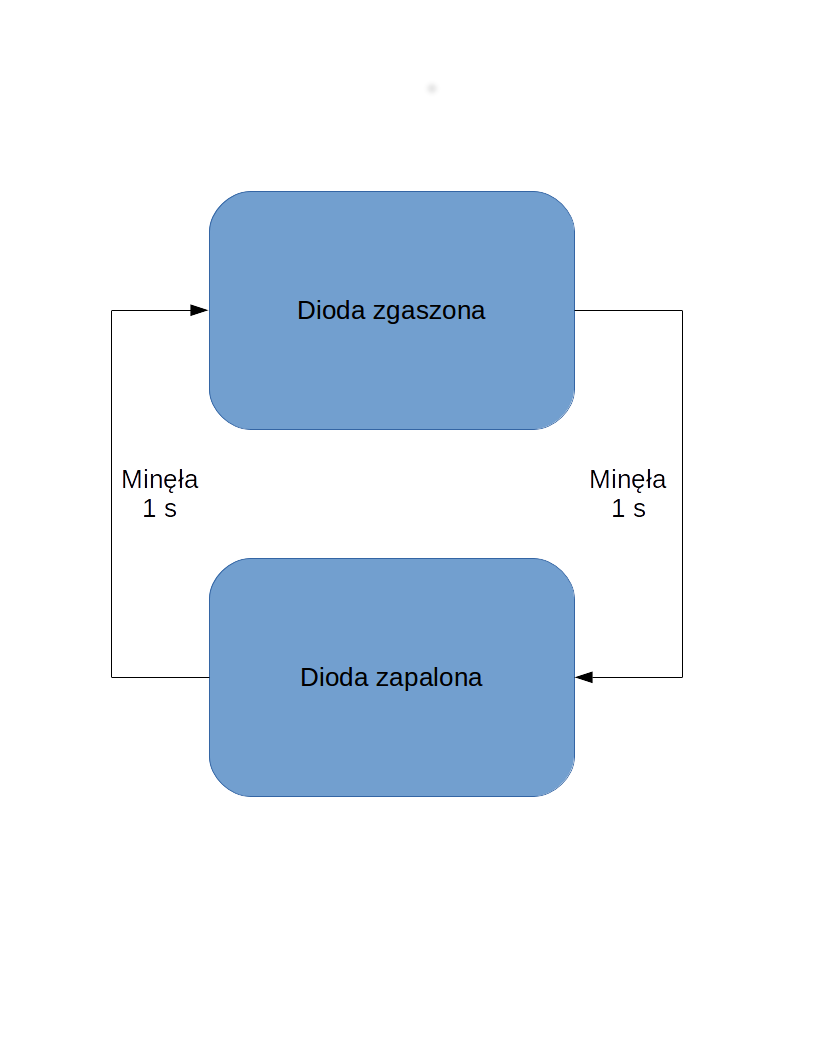 Kod realizujący taki diagram na Arduino:
Kod realizujący taki diagram na Arduino:
unsigned long czas; #define LED 9 void setup() { // put your setup code here, to run once: pinMode(LED, OUTPUT); digitalWrite(LED, LOW); czas = millis(); } #define ST_OFF 1 #define ST_ON 2 byte state = ST_OFF; void loop() { // put your main code here, to run repeatedly: switch (state) { case ST_OFF: digitalWrite(LED, LOW); if (millis() - czas > 1000) { state = ST_ON; czas = millis(); } break; case ST_ON: digitalWrite(LED, HIGH); if (millis() - czas > 1000) { state = ST_OFF; czas = millis(); } break; } }
Co my tutaj mamy:
unsigned long czas; #define LED 9
W zmiennej czas będziemy zapamiętywać czas zdarzenia (by nie używać delay) i odmierzać upływ sekundy. Dioda jest podłączona do portu 9, stąd taka wartość etykiety LED. Funkcja setup nie omawiamy, bo jest mało interesująca w kontekście tego postu.
Przejdźmy do kolejnych definicji:
#define ST_OFF 1 #define ST_ON 2 byte state = ST_OFF;
Mamy dwa stany ST_OFF i ST_ON odpowiadające naszym stanom z diagramu. To co ważne – wartości przypisane do stanów MUSZĄ być unikalne, nie mogą się powtarzać. To chyba oczywiste dlaczego?
Zmienna state przechowuje nasz aktualny stan. I tutaj bardzo ważna sprawa – nadaj wartość od razu zmiennej state tak by od razu znalazła się w stanie w jakim na początku ma być układ (tutaj – zgaszona dioda czyli ST_OFF).
No to teraz przejdźmy do loop, w którym dokona się magia naszych przejść pomiędzy stanami:
switch (state) { case ST_OFF: digitalWrite(LED, LOW); if (millis() - czas > 1000) { state = ST_ON; czas = millis(); } break; case ST_ON: digitalWrite(LED, HIGH); if (millis() - czas > 1000) { state = ST_OFF; czas = millis(); } break; }
Komenda switch(state)/case wybiera kod, który wykona się gdy wartość zmiennej state jest równa wartości podanej po case. Czyli jeśli wartość state jest 1 (ST_OFF) to wykona się kod po case ST_OFF:
Wykona się aż do komendy break, jeśli jej zabraknie, wykona się również kod po następnym case więc nie zapomnij o tym break.
Co za kod jest w wypadku gdy stan jest ST_OFF?
digitalWrite(LED, LOW); if (millis() - czas > 1000) { state = ST_ON; czas = millis(); }
Gasimy diodę i sprawdzamy czy w tym stanie przebywa dłużej niż sekundę (millis() – czas podaje ile milisekund upłynęło od czasu zapisanego w zmiennej czas). Jeśli nie upłynęło co najmniej 1000 ms (czyli owa jedna sekunda) to nic się nie dziej, natrafiamy na break i pętla loop się wykonuje dalej. Jeśli jednak upłynęło 1000 ms, wówczas bieżący stan zapisany w state jest zmieniany na ST_ON (to jest właśnie ta strzałka z tego diagramu wyżej) i zapamiętywany w zmiennej jest czas tego zdarzenia. Dzięki temu wykona się następny kod po następnym case, który zapala diodę. Podobnie odmierza jedną sekundę i jeśli ona upłynie stan zmieniany jest ponownie na ST_OFF i cykl się powtarza.
Jest bardzo uproszczony przykład. Jeśli się zastanowić, to powinniśmy dostrzec, że są tutaj tak naprawdę cztery stany:
- Zgaszenie diody
- Odczekanie 1 sekundy
- Zapalanie diody
- Odczekanie 1 sekundy
Co za różnica? Teraz w każdym przebiegu pętli loop stan wyjścia jest ustawiany na LOW lub HIGH. W tym przypadku nie ma to znaczenia funkcjonalnego, ale jeżeli np zamiast gasić diodę Arduino miałoby np wysłać jakaś daną np prze SPI czy I2C robiło by to za każdym razem gdy pętla loop się wykonuje. Zamień sobie digitaWrite(LED,LOW) w przykładowym kodzie na fikcyjną funkcję sendDataToISS() a zrozumiesz chyba dobrze na czym polega ten problem. Jak temu zapobiec? Ano, wprowadzamy dwa dodatkowe stany ST_WAIT1, ST_WAIT2 i kod wygląda teraz tak:
#define ST_OFF 1 //dioda wyłączana #define ST_WAIT1 2 //czekamy na zapalanie #define ST_ON 3 //zapalamy diodę #define ST_WAIT2 4 //czekamy na zagaszenie byte state = ST_OFF;
Przypominam, by się pilnować aby wartości stanów się nie powtarzały. Druga uwaga – opisuj sobie, który stan co znaczy. Bo albo będziesz używał strasznie długich etykiet albo łatwo się będzie pogubić. Jak teraz wygląda nasz switch?
switch (state) { case ST_OFF: digitalWrite(LED, LOW); state = ST_WAIT1; break; case ST_WAIT1: if (millis() - czas > 1000) { state = ST_ON; czas = millis(); } break; case ST_ON: digitalWrite(LED, HIGH); state = ST_WAIT2; break; case ST_WAIT2: if (millis() - czas > 1000) { state = ST_OFF; czas = millis(); } break; }
Czemu mamy dwa stany czekania? Dlatego, że po zakończeniu oczekiwania przechodzimy do różnych stanów następnych. Raz jest to ST_OFF a raz ST_ON. Nasz nowy, uaktualniony diagram wygląda tak:
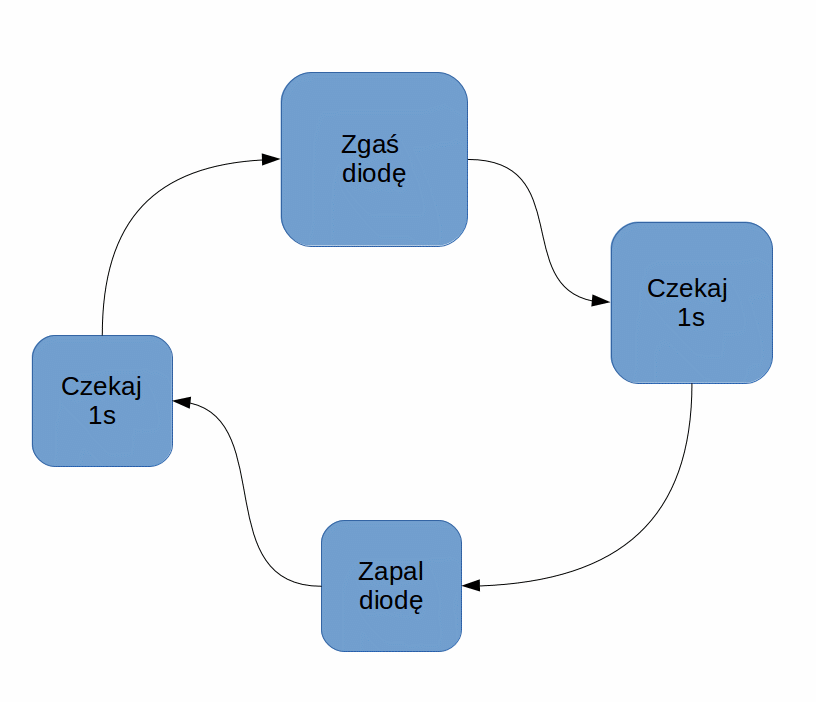 Czego tutaj brakuje? Powinniśmy zawsze zaznaczyć punkt startu – w naszym szkicu zapewnia to nam definicja
Czego tutaj brakuje? Powinniśmy zawsze zaznaczyć punkt startu – w naszym szkicu zapewnia to nam definicja byte state = ST_OFF dzięki czemu zawsze zaczynamy od zgaszenia diody.
Były to bardzo proste przykłady. Głównie dlatego, że przejścia między stanami są bardzo proste – z każdego stanu jest tylko jedno przejście. Przejścia mogą być bardziej różnorodne.
Zaletą takiego podejścia,że jeżeli logika nakazuje w jakimś przypadku wrócić gdzieś daleko to nie jest to trudne. Wystarczy zmienić jedną zmienną i zaczynamy proces we wskazanym miejscu.
Wróćmy do naszego przykładu – mając omówione przykłady myślę że bez trudu zrozumiecie działanie maszyny. Najpierw szkic, który określa nasz diagram stanów:
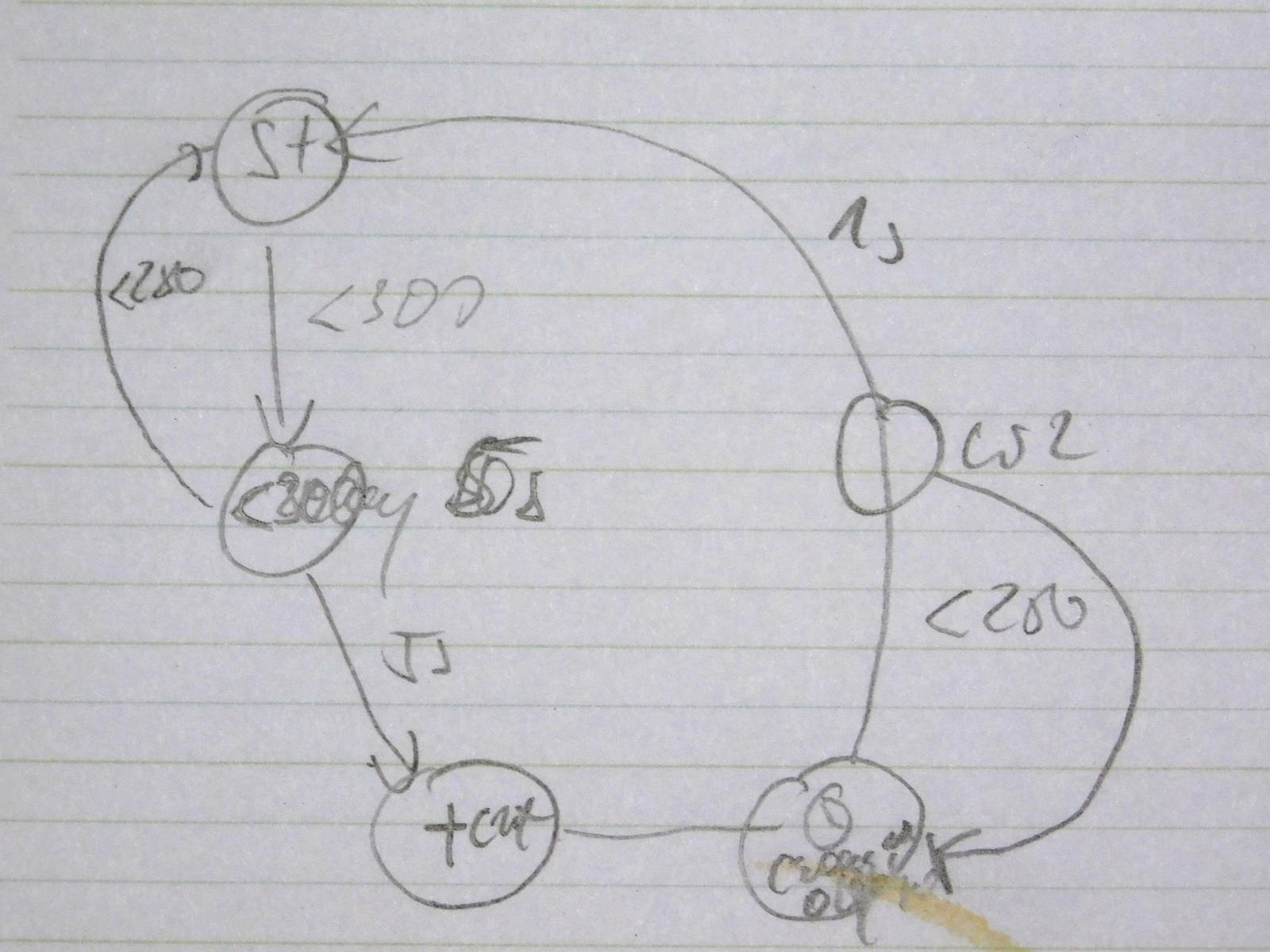
Schemat ten doskonale ilustruje zalety takiego podejścia. Od reki został wymyślony jakiś ale w trakcie analizy na kartce z ołówkiem okazało się że brakuje nam tego stanu. Można było dorysować i dodatkowe przejście między nimi. Gdy tak analiza na sucho już wskazywała że powinno działać, pozostało zaimplementować to w kodzie.
Najpierw definicje:
#define ST_INIT 0 #define ST_CLOSE 1 #define ST_COUNT 2 #define ST_WAITING 3 #define ST_WAITING2 4 #define CLOSE_LEVEL 310 #define LEAVE_LEVEL (CLOSE_LEVEL-20) #define WAIT_SECS SECS(3) #define LEAVE_SECS SECS(1)
Znaczenie etykiet ST_ jest chyba jasne – są to kolejne stany z diagramu którego zdjęcie widzieliście wcześniej. CLOSE_LEVEL i LEAVE_LEVEL to wartości progowe odczytu z czujnika dla których następuje zaliczenie podejścia i odejścia. WAIT_SECS oraz LEAVE_SECS to wartości zgodne z biblioteką Timers – jest ona używana do odmierzania czasu (więcej o niej w tym wpisie).
Teraz popatrzmy na nasz switch, który w przypadku maszyny stanów jest zwykle sercem całego programu:
switch (state) { case ST_INIT: if (reading > CLOSE_LEVEL) { state = ST_CLOSE; timer.begin(WAIT_SECS); } break; case ST_CLOSE: if (reading < LEAVE_LEVEL) { state = ST_INIT; timer.begin(0); } if (timer.available()) { timer.begin(0); state = ST_COUNT; } break; case ST_COUNT: count++; state = ST_WAITING; break; case ST_WAITING: if (reading < LEAVE_LEVEL) { timer.begin(LEAVE_SECS); state = ST_WAITING2; } break; case ST_WAITING2: if (reading > CLOSE_LEVEL) { state = ST_WAITING; timer.begin(0); } if (timer.available()) { state = ST_INIT; timer.begin(0); } break; }
Weźmy na warsztat pierwszy stan:
case ST_INIT: if (reading > CLOSE_LEVEL) { state = ST_CLOSE; timer.begin(WAIT_SECS); }
Jeśli reading (wartość sygnału z czujnika) przekracza naszą wartość krytyczną to zmieniamy stan na następny, jednocześnie uruchamiamy timer, który będzie odliczał WAIT_SECS. W ifie jest sprawdzanie czy reading jest większe od wartości bo to jest odczyt z czujnika IR Sharpa, który zwraca większe napięcie im bliżej wykryty obiekt. Dlatego jeśli reading jest większe niż wartość progowa to znaczy że obiekt jest blisko. Skoro wykryliśmy zbliżenia się głowy, to teraz mamy odczekać odpowiednią ilość sekund. Gdy przed upłynięciem czasu głowa się oddali, to mamy przerwać zliczanie czasu. Jak to wygląda w kodzie:
case ST_CLOSE: if (reading < LEAVE_LEVEL) { state = ST_INIT; timer.begin(0); } if (timer.available()) { timer.begin(0); state = ST_COUNT; } break;
W tym stanie mamy sprawdzane za każdym razem dwa ify. Pierwszy, jeśli głowa się oddali (Sharpy mają mniejszy odczyt gdy coś jest dalej) to wracamy do stanu ST_INIT i zatrzymujemy (zerujemy) licznik. Drugi if – jeśli licznik dotrwał do końca, przechodzimy do stanu w którym dokonamy zliczenia. Dlaczego od razu nie zliczyć tutaj zbliżenia i np zrobić po prostu count++? Z praktyki podpowiem – stany lepiej niech będą operacjami atomowymi, tzn by logicznie nie dały się podzielić na kilka stanów. Jeśli w przyszłości zliczenia trzeba będzie dokonać jaki rezultat wyjścia z jeszcze innego stanu, to trzeba będzie więcej kodu przepisać. A tak, mamy gotowy stan
Jak z każdą zasadą trzeba umieć ją stosować z umiarem. Nie za wszelką cenę każdą operację w oddzielnym stanie, jak Ci wygodniej i nie przewidujesz zmian to możesz w jednym stanie robić wiele operacji, nawet jeśli logicznie można by je rozdzielić.
OK, to mamy ogarniętą maszynę stanu, ale dla jednego czujnika. Jak zrobić dla drugiego jednocześnie? W tym wypadku mamy dwa czujniki i obie maszyny stanów są identyczne. Tzn takie same wartości, czasy, przejścia. Skorzystamy z funkcji – samo sprawdzenie wsadzimy do niej, a jako argumenty będziemy podawać zmienne dotyczące wybranego czujnika.
void test_status(byte &state, unsigned int reading, Timer &timer, long unsigned int &count) { switch (state) { //KOD }
KOD to jest ten switch, który podany był wcześniej. W definicji funkcji część argumentów ma znak & przed nazwą. Bez niego modyfikacja np state nie ’wyszłaby poza funkcję’. Czyli zmieniamy stan w funkcji, wychodzimy a wartość zmiennej state jest jaka była. Z użyciem & zmiany wprowadzone podczas wykonywania funkcji są widoczne po jej opuszczeniu.
Timer timer1; Timer timer2; byte state1 = ST_INIT; byte state2 = ST_INIT; unsigned rd = analogRead(A0); test_status(state1, rd, timer1, cnt); unsigned rd = analogRead(A1); test_status(state2, rd, timer2, cnt);
Wycinek kodu pokazujący jak to działa. Deklarujemy dwie pary zmiennych timer i state każdą dla jednego czujnika. Potem tylko odczytujemy wartość z czujnika podpiętego do A0/A1 i sprawdzamy stan maszyny, czy nastąpiły przejścia. Ot, z grubsza całość.
Ten akurat kod programu robił jeszcze dodatkowe rzeczy – obsługiwał wyświetlanie na LCD oraz zapis danych do EEPROM, tak by wartość licznika nie uległa zapomnieniu. Przy czy, do EEPROM zapisywał wartość tylko jeśli uległa zmianie i co kilkanaście minut. Wszystko po to by ograniczyć liczbę zapisów. Zapisując po każdej zmianie, moglibyśmy doprowadzić do tego, że EEPROM ulegnie uszkodzeniu (ma ograniczoną liczbę zapisów). Dzięki takiemu podejściu w razie utraty zasilania tracimy co najwyżej dane z kilkunastu minut, a przewidywany czas działania licznika to były tygodnie, więc taka strata danych była przez klienta dopuszczona jako akceptowalna. Zwłaszcza że projekt powstawał na klasyczne na wczoraj i głównym celem było zapewnienie podstawowej funkcjonalności i poprawności…
Jak już przy tym temacie jesteśmy – tak od pewnego czasu jesteśmy dostępni do prac na zlecenie – jeżeli masz jakiś projekt wymagający integracji elektroniki, programowania, czujników itp – napisz do nas na info@nettigo.pl chętnie pomożemy.
Nie łatwiej wstawić zegar?
Tylko jeśli z ładnym cyferblatem….